hdfs文件系统,hdx中国
时间:2024-11-26 来源:网络 人气:
深入解析HDFS文件系统:架构、特性与编程实践
随着大数据时代的到来,对海量数据的存储和处理需求日益增长。HDFS(Hadoop Distributed File System)作为Apache Hadoop的核心组件之一,为大规模数据存储提供了高效、可靠的解决方案。本文将深入解析HDFS文件系统的架构、特性以及编程实践,帮助读者全面了解这一分布式文件系统。
一、HDFS的架构
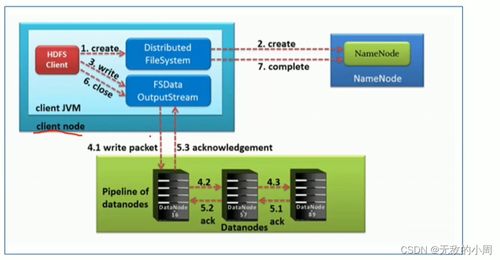
HDFS采用主从架构,主要由NameNode和DataNode组成。
NameNode:HDFS的主节点,负责管理文件系统的命名空间,记录文件如何分割成数据块,以及这些数据块分别存储在哪些DataNode上。
DataNode:HDFS的从节点,负责实际存储数据块,并定期向NameNode发送它们所存储的块的列表。
二、HDFS的特性
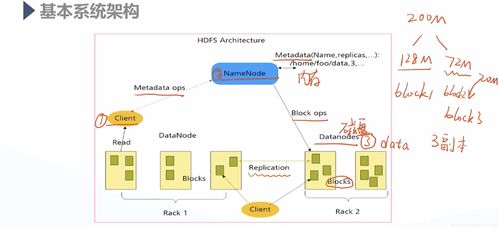
HDFS具有以下特性:
高容错性:通过数据复制机制,确保数据的高可用性和容错性。每个数据块默认有3个副本,分布在不同的DataNode上。
高吞吐量:针对大文件的存储和访问进行了优化,适合顺序读写操作。
流式访问:允许数据流式访问,用户可以在数据写入的同时进行读取。
异构软硬件平台间可移植:支持在异构软硬件平台上运行。
三、HDFS的数据复制
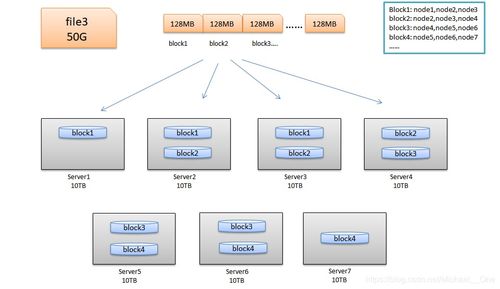
HDFS通过数据复制机制确保数据的高可用性和容错性。以下是数据复制的主要过程:
当NameNode接收到一个数据块的写入请求时,它会将数据块分配给一个或多个DataNode进行存储。
数据块在DataNode上存储后,NameNode会记录数据块的副本信息。
当NameNode检测到某个DataNode故障时,它会自动从其他副本中恢复数据块。
四、HDFS的编程实践

以下是一个使用Java API在HDFS上创建文件的示例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileCreate {
public static void main(String[] args) throws IOException {
// 创建HDFS配置对象
Configuration conf = new Configuration();
// 添加HDFS配置文件路径
conf.addResource(new Path(
相关推荐

教程资讯
教程资讯排行